Overview
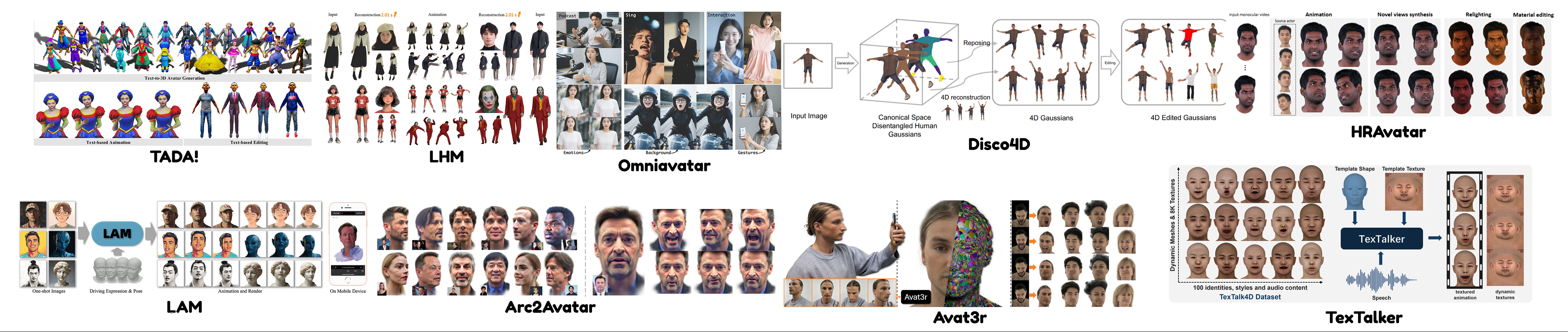
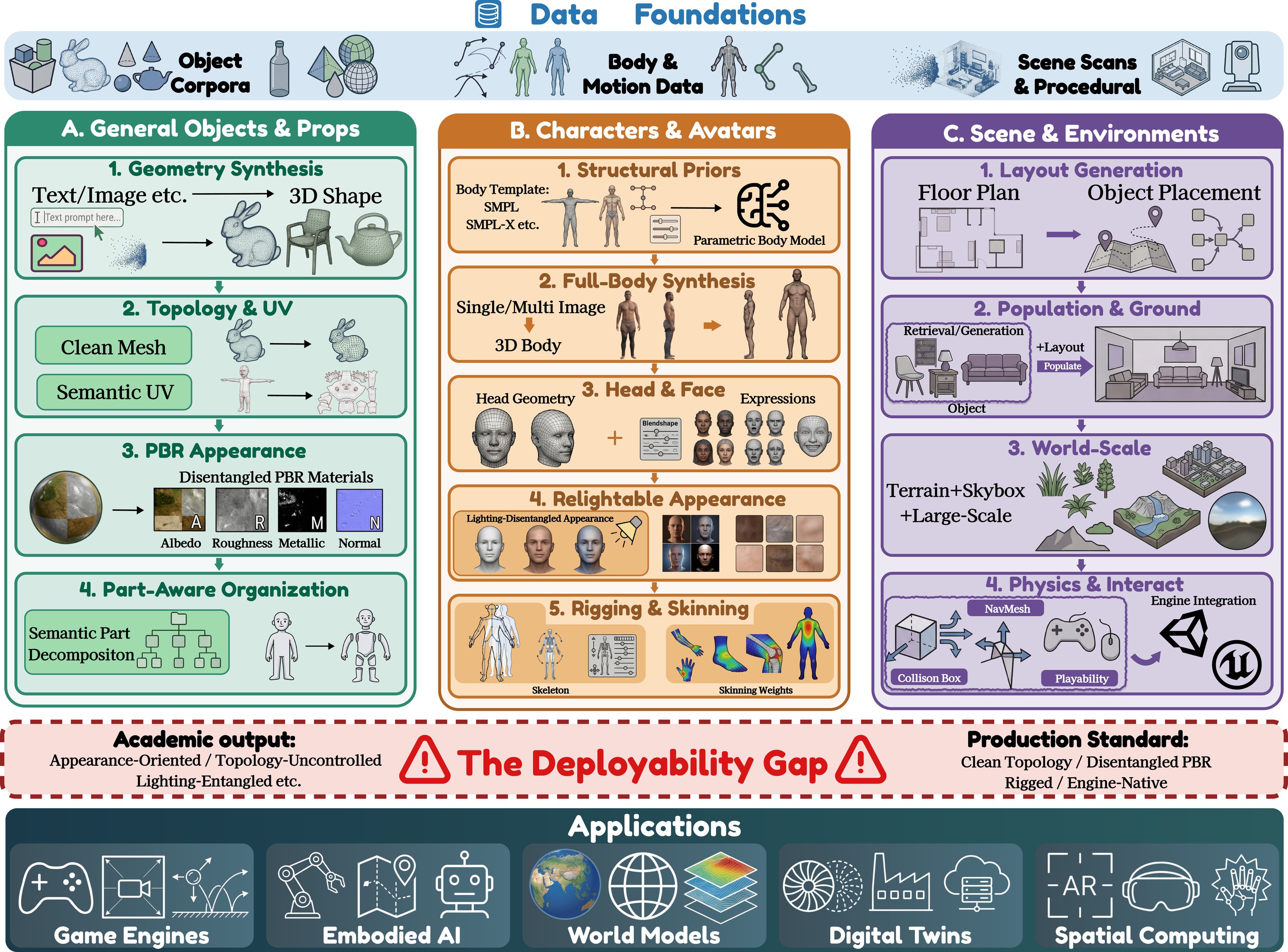
Three-dimensional content generation has progressed from producing isolated, visually plausible shapes to constructing structured assets that can be deployed in real-time interactive environments. This trajectory is driven by converging demands from game development, embodied AI, world simulation, digital twins, and spatial computing, all of which require 3D content that goes beyond surface appearance to satisfy engine-level constraints on topology, UV parameterization, physically based materials, skeletal rigging, and physics-aware scene layout. Despite rapid advances in generative modeling, a persistent gap separates the outputs of current methods from the production-ready standard expected by interactive applications. This survey addresses that gap by organizing the literature around the asset production pipeline rather than algorithmic families. Along the horizontal axis we distinguish three asset tiers—namely general objects, characters, and scenes—while the vertical axis traces each tier through the full production lifecycle from data foundations and geometry synthesis through topology optimization, UV unwrapping, PBR appearance, rigging, and scene assembly. Through this two-dimensional taxonomy we assess not only what current methods can generate but whether their outputs are directly usable in downstream engines and simulation platforms. We further consolidate evaluation metrics and protocols that span geometric fidelity, appearance quality, asset usability, and scene-level physical plausibility. The survey concludes by identifying open challenges in data quality, generation controllability, end-to-end assetization, and physically grounded generation, and by situating production-ready 3D content as foundational infrastructure for emerging interactive world models and embodied intelligent systems.